
Raftokay: Building Raft Consensus From Scratch
A deep dive into implementing Raft consensus in Go: leader election, log replication, persistence, and chaos testing included.
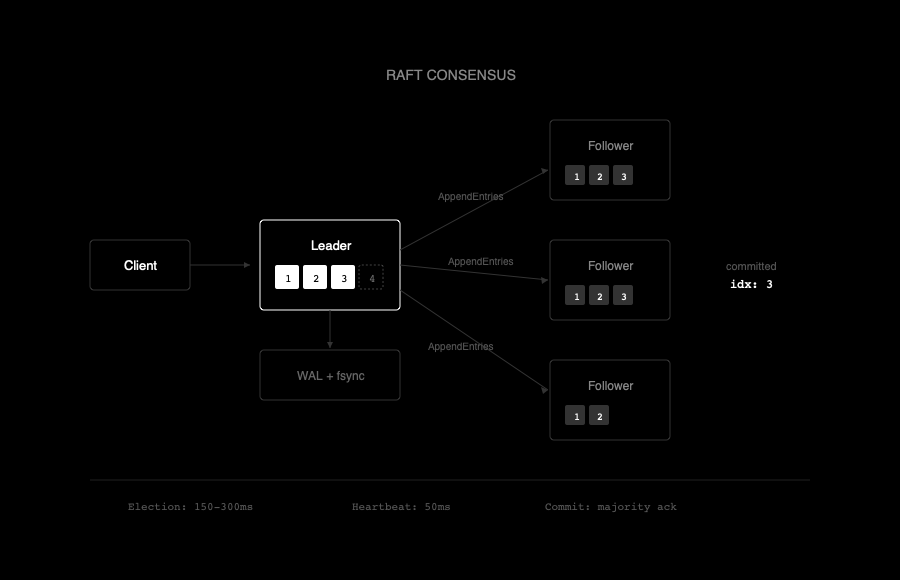
Inside Raftokay
A production-ready Raft implementation built in Go, with WAL persistence, snapshots, and a chaos simulator to prove it actually works.
Why Build Raft From Scratch?
Everyone reaches for etcd or Consul when they need consensus. Fair enough, they're battle-tested.
But here's the thing: if you don't understand what's happening underneath, you're flying blind when things break. And in distributed systems, things break in ways that make you question reality.
Raftokay exists because:
This isn't a toy. It persists to disk. It recovers from crashes. It survives network partitions.
The Raft Algorithm (30-Second Version)
Raft solves distributed consensus: getting multiple machines to agree on a sequence of operations even when some machines crash or networks fail.
The core insight is brutal simplicity: one leader, everyone else follows. The leader:
1. Accepts client requests
2. Replicates them to followers
3. Commits them once a majority acknowledges
If the leader dies, followers elect a new one. That's it. No complex multi-phase commits. No Byzantine fault tolerance. Just "follow the leader" with elections when needed.
Leader Election: Randomized Chaos Control
The election mechanism is elegant in its paranoia. Every server runs a timer. If it doesn't hear from a leader before the timer expires, it assumes the leader is dead and starts an election.
The trick is randomized timeouts:
// Election timeout: 150-300ms randomized
electionTimeout := 150 + rand.Intn(150)Why random? Because simultaneous elections cause split votes. If all servers timed out at exactly 200ms, they'd all start elections, all vote for themselves, and no one would win. Randomization breaks symmetry.
The state machine is clean:
Transitions are explicit:
follower → candidate (election timeout)
candidate → leader (won election)
candidate → follower (discovered higher term)
leader → follower (discovered higher term)No ambiguous states. No edge cases hidden in boolean flags.
Log Replication: The Real Work
Leader election is flashy, but log replication is where consensus actually happens.
When the leader receives a command:
1. Appends it to its local log with the current term number
2. Sends AppendEntries RPCs to all followers
3. Waits for a majority to acknowledge
4. Commits the entry and applies it to the state machine
5. Notifies followers to commit on the next heartbeat
The consistency check is critical:
// Reject if log doesn't contain entry at prevLogIndex with prevLogTerm
if prevLogIndex > 0 {
if len(rf.log) < prevLogIndex || rf.log[prevLogIndex-1].Term != prevLogTerm {
return false
}
}This ensures followers have an identical log prefix before accepting new entries. If they don't, the leader backtracks until it finds the point of divergence and overwrites the follower's log.
Aggressive? Yes. But it guarantees that once an entry is committed, it's committed forever.
Persistence: Because Memory is a Lie
Here's where most "educational" Raft implementations cheat: they skip persistence.
In production, servers crash. Power fails. Disks get replaced. If your consensus algorithm only works when nothing ever restarts, it's not a consensus algorithm. It's a demo.
Raftokay uses a write-ahead log (WAL):
// Every write is immediately fsynced
func (w *WAL) Append(entry Entry) error {
encoded := gob.Encode(entry)
if _, err := w.file.Write(encoded); err != nil {
return err
}
return w.file.Sync() // fsync after every write
}The Sync() call is non-negotiable. Without it, your "persisted" data lives in the OS buffer cache, which dies with the power.
On startup, the server replays the WAL to reconstruct state:
1. Load persisted term and votedFor
2. Replay log entries
3. Load snapshot if available
4. Resume operation
Crash at any point? No problem. The WAL contains everything needed to recover.
Snapshots: Log Compaction
Logs grow forever. That's a problem.
If a server ran for a year without compaction, its log would contain millions of entries. Recovery would take hours. Disk usage would explode.
Snapshots solve this:
1. Serialize the current state machine to disk
2. Record the last included log index and term
3. Truncate the log before that point
4. Continue appending new entries
For slow or recovering followers, the leader sends snapshots via InstallSnapshot RPC instead of replaying thousands of entries.
// Truncate log after snapshot
func (w *WAL) TruncateBefore(index uint64) error {
// Keep only entries after snapshot point
w.entries = w.entries[index:]
return w.rewrite()
}The result: bounded log size, fast recovery, and efficient catch-up for lagging nodes.
Chaos Testing: Break Everything on Purpose
Unit tests are necessary but insufficient. They test the algorithm in isolation. Production involves:
Raftokay includes a chaos simulator that injects all of these:
// Simulate network partition
sim.Partition([]int{0, 1}, []int{2, 3, 4})
// Delay messages by 100-500ms
sim.AddLatency(100, 500)
// Drop 10% of messages
sim.SetDropRate(0.1)
// Heal partition and verify consistency
sim.HealPartition()The simulator runs hundreds of operations while chaos is active, then verifies:
If Raft can survive simulated chaos, it has a shot at surviving real infrastructure.
Code Highlights
A few implementation decisions worth noting:
Single-threaded state machine: All Raft state mutations happen in one goroutine. RPCs and timers send messages to this goroutine via channels. This eliminates lock contention and makes reasoning about state trivial.
Term as the source of truth: Whenever a server sees a higher term, it immediately becomes a follower. No exceptions. This ensures stale leaders can't cause damage.
Commit rule safety: Leaders only commit entries from the current term. This prevents a subtle bug where a new leader could prematurely commit entries from a previous term that hadn't actually achieved consensus.
// Only commit entries from current term
if entry.Term == rf.currentTerm && matchCount > len(rf.peers)/2 {
rf.commitIndex = index
}Running It
The repo includes raftd (the server daemon) and raftctl (the CLI tool).
Start a 3-node cluster:
raftd --id 1 --peers "localhost:8001,localhost:8002,localhost:8003"
raftd --id 2 --peers "localhost:8001,localhost:8002,localhost:8003"
raftd --id 3 --peers "localhost:8001,localhost:8002,localhost:8003"Submit commands:
raftctl set foo bar
raftctl get foo
# barKill a node, submit more commands, restart it, verify it catches up. That's the whole point.
Summary
Raftokay is a Raft implementation that doesn't cut corners:
It's not meant to replace etcd. It's meant to teach you what etcd is actually doing, so when your production cluster starts misbehaving at 3 AM, you'll understand why.
Distributed systems don't reward ignorance. Study the algorithm. Read the code. Break things in simulation before production breaks them for you.